








开云体育 
芯片受限又如何?DeepSeek V4 凭算法逆袭有望改写全球 AI 开云APP下载格局
 2026-01-17
2026-01-17 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!备年货,DeepSeek偏要备“大招”。这个每逢假期必发新品的中国AI团队,这次把矛头对准了编程界的“顶流”Claude。
核心问题很直接:春节前后登场的DeepSeek V4,真能撼动Claude的编程王座吗?
熟悉这个团队的人都记得,去年1月20日春节前夕,他们的R1模型横空出世,直接在全网掀起了一场AI地震。
那次发布后来被视作行业教科书级别的操作,讨论热度、传播范围和社区反馈全冲到了峰值。这次V4选在同一时段登场,明眼人都能看出来,他们是想复刻R1的春节“核爆”名场面。
最初V3模型崭露头角,第一次让国际开发者正经打量起这个中国团队;线,这款开源推理模型把“先思考再作答”变成了看得见的过程,用相对克制的训练成本,实现了复杂问题处理的惊人稳定性。
这种“低成本高回报”的反差,直接戳中了硅谷最敏感的神经。之后他们把R1和V3的能力整合进国内聊天应用,短时间内就成了现象级产品。
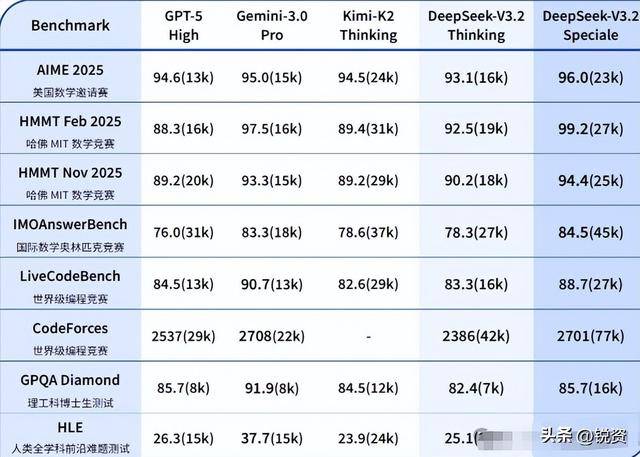
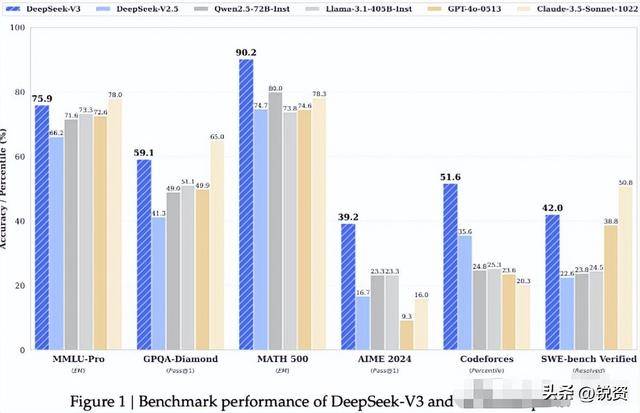
2025年一年里,V3.1、V3.2等迭代版本接连问世,还植入了智能体能力,上个月推出的V3.2更在部分基准测试中直接碾压GPT-5和Gemini 3.0 Pro,没发换代模型就实现了反超,这也让外界对V4的期待值拉到了顶点。
第一个杀招就是编程能力的“超车”,内部测试数据显示,它在编程任务上的表现已经超过了Claude、GPT系列等主流模型,要是消息属实,DeepSeek就能从追赶者直接跃升为领跑者,至少在编程这个AI核心赛道上占据优势。
第二个杀招是超长上下文代码处理能力,这对普通用户可能感知不强,但对大型项目的软件工程师来说,绝对是革命性的提升。
想象一下,面对一个几万行代码的项目,以前的模型往往会忘记前面的代码,在长上下文中迷失方向。
而V4能一次性吃透整个代码库的上下文,精准完成新功能插入、bug修复和重构,这对企业级开发来说,无疑是一场生产力革命。
第三个杀招是算法“抗衰”能力,模型在训练各阶段对数据模式的理解更深刻,还不容易出现能力衰减,不用靠堆芯片数量就能缓解问题。
第四个杀招则是更严密可靠的推理能力,用户能明显感觉到它的输出逻辑更清晰,关键是这种提升没有以牺牲其他性能为代价,在AI领域,不出现性能退化本身就是极高的评价。
CEO梁文锋近期参与合著的论文也透露,他们研发了全新训练架构,不用按比例增加芯片,就能支撑更大规模模型的扩展。
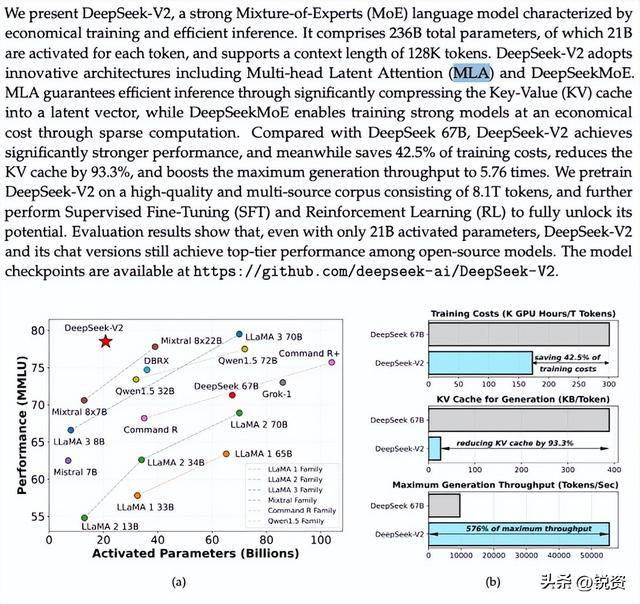
核心之一是MoE混合专家架构,V3拥有6710亿总参数,但推理时每个token只激活约370亿参数,这种稀疏激活机制让模型在保持大规模的同时,兼顾了极高的推理效率。
他们还改进了传统MoE的训练方法,用“细粒度专家+通才专家”的策略,更好地覆盖多维知识空间。
另一个关键技术是MLA多头潜在注意力机制,从V2时代就开始应用,通过压缩键和值张量到低维空间,大幅减少了推理时的内存占用,性能还优于传统的分组查询注意力。
更重要的是,V4很可能继承了R1的强化学习优化经验,把V3的基础能力和R1的推理优势完美融合。
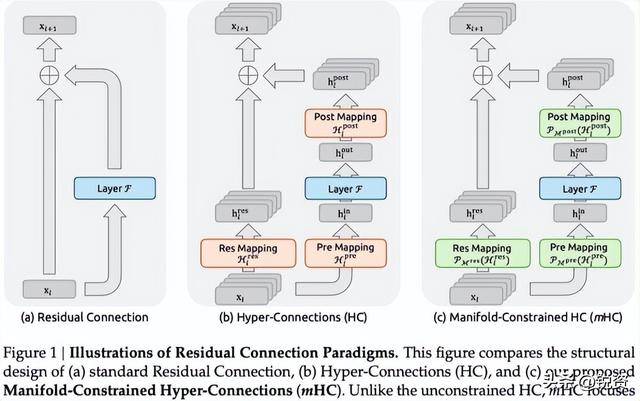
再加上2025年12月31日发布的mHC流形约束超连接技术,更是解决了困扰行业十年的大模型训练不稳定性问题,把信号放大从3000倍压缩到1.6倍,仅增加6.7%的训练开销,还在270亿参数模型上得到了验证。
36氪1月13日的报道还揭秘了V4的另一张技术底牌,那就是Engram记忆模块。
这个模块通过“存储固定知识直接查询”的方式解放模型算力,最关键的是能让普通CPU内存替代昂贵的GPU显存,即便把1000亿参数的模型放在CPU内存上推理,吞吐量损耗也不到3%,完美契合DeepSeek一贯的高性价比路线。
受芯片出口限制影响,DeepSeek没有走拼硬件数量的路子,而是专注于算法效率的提升。
就像V3的训练成本仅557.6万美元,远低于OpenAI、Google同级别模型几十倍的投入,这种“用更少资源做更好模型”的能力,是算法、框架和硬件协同优化的结果,V4大概率会延续这条路线已在“野区”测试?更多惊喜待解锁
有用户在大模型竞技场LMArena上发现了一个匿名模型,传闻就是V4,但由于模型存在“撒谎”的可能,目前还无法最终确认。
GIGAZINE 1月14日援引外媒报道称,V4预计会在2月17日左右正式发布,内部测试中已经超越了Claude 3.5 Sonnet和GPT-4o,而且DeepSeek近期更新了R1模型白皮书,披露了其三阶段训练流程,这很可能是在为V4的技术落地做铺垫。
版本,当年R1发布时,就同步推出了一系列蒸馏版本,让普通用户能在消费级硬件上体验强化学习推理模型,V4会不会延续这个亲民策略?其次是多模态能力的表现,目前所有报道都聚焦在编程上,但V4在图像、音频等多模态领域是否有提升,还是个未知数。
再者是API定价,DeepSeek一直走极致性价比路线编程能力真的超越Claude,价格却只有几分之一,绝对会给整个市场带来巨大冲击。
许可开源,但编程领域商业价值极高,V4乃至后续的V5、V6是否还会坚持开源,成为行业关注的变量。这里也要提醒大家,南方+客户端此前已经辟谣了“V4已发布”等不实信息,强调DeepSeek的官方信息要以其官方账号为准,大家要注意甄别非官方传言。
如果V4真能在硬件受限的条件下,实现对Claude编程能力的超越,那绝对是极具象征意义的里程碑。
它将用实际成果证明,在AI竞赛中,聪明的算法完全可以弥补硬件的不足,为硬件受限的企业和团队指明新的方向。
这种突破带来的行业影响将是全方位的。首先会重塑编程AI赛道的格局,打破Claude目前的垄断地位,让中国AI在全球开源AI领域的领导地位进一步巩固。
要知道2025年中国大厂和初创公司密集发布并开源模型,已经把中国AI的行业存在感抬升了一个量级。
其次会启发行业转向“效率至上”的新方向,推动整个AI行业从拼硬件数量的粗放模式,转向拼算法效率的精细化发展,这对全球AI技术的良性发展至关重要。最后会深刻变革企业级开发模式,V4的超长上下文处理能力能大幅提升复杂项目的开发效率,降低企业的研发成本,让AI技术更好地服务于产业升级。
36氪的报道就指出,Engram技术一旦在V4上落地,不仅能让超大规模模型的部署成本大幅降低,还能让垂直行业的维护成本呈指数级下降,甚至可能重塑整个行业构建基础模型的方式。
其实DeepSeek早就用V3证明过这种高性价比路线以远低于行业巨头的训练成本实现高性能,成为AI圈的“性价比典范”,这次V4很可能复制甚至超越这种影响力。
吴晓波在《AI闪耀中国》演讲中提到的,中国AI侧重开源大模型及“从1到N”的产业化应用,而DeepSeek的探索正是这种方向的生动实践,用技术创新在真实场景中释放AI的价值。把春节过成AI发布会,DeepSeek这波操作足够让人期待。
V4的四大杀招加上一贯的高性价比buff,让这场编程王座挑战赛充满看点。
无论最终能否实锤超越Claude,其在硬件限制下的算法创新,都已经为中国AI企业树立了标杆。
距离发布不足一月,让我们蹲守春节档,看这场AI圈的巅峰对决最终走向何方。
