








开云体育 
开云体育DeepSeek驱动的高效多机推理方案设计与工程实践_通信世界网
 2025-07-10
2025-07-10 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!DeepSeek通过优化算法架构,显著提升了算力利用效率,打破了算力至上的传统认知,围绕AI三要素(算力、算法、数据),从成本竞争(堆砌算力)又拉回到技术竞争(创新算法)的道路上。
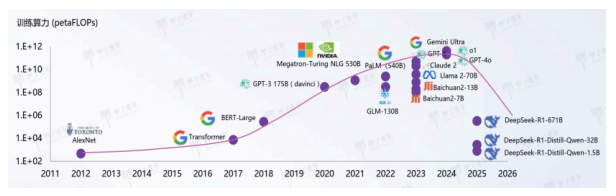
随着大模型生产成本的降低以及发布模型的变更,后DeepSeek时代将更注重AI和应用的结合,所以在未来“推理为主+少量微调”的场景是智算的主流发展趋势,AI应用开发商和AI终端客户将成为核心客户。
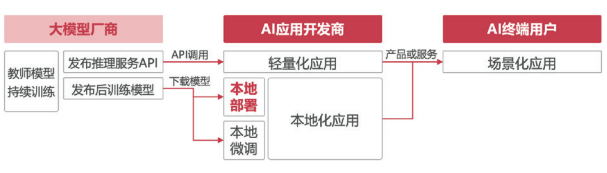
对于AI应用开发商来说,需要构建高效软硬一体化的训推开发环境,满足模型快速迭代,对于AI终端用户而言,需要提供大模型推理服务,快速对接AI场景化应用。
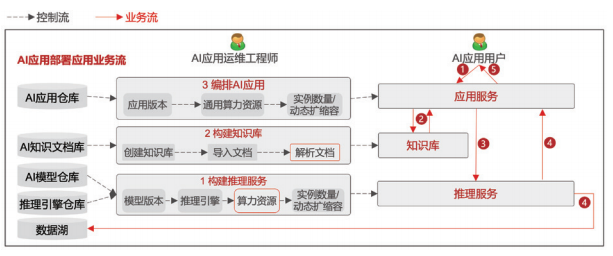
首先,用户通过AI应用提交问题或数据。随后,应用服务对用户输入进行解析,依据自然语言处理与语义分析技术,从预先构建的知识库中匹配相关知识,这一过程旨在为后续推理提供必要的背景信息与知识支撑。应用服务将从知识库获取的知识与用户提交的问题或数据相结合,通过特定的算法与规则形成提示词,将其输入到推理服务模块。推理服务接收到提示词后,调用AI模型进行运算,生成推理结果。若客户部署了数据回流模块,该模块会自动收集推理结果,这些数据后续将成为微调模型的重要数据集,助力模型性能的持续优化。最终,应用服务将推理计算结果以可视化或结构化的形式呈现给用户,完成整个交互闭环。
在AI应用落地过程中,推理方案的设计质量直接决定了业务的效率、成本与可扩展性。一个科学合理的推理方案需以业务本质为出发点,构建技术适配性与商业可持续性兼具的架构体系。其核心在于通过系统化的设计逻辑,将业务需求转化为可落地的技术方案,既要精准匹配当前算力资源与模型特性,又需为未来业务增长预留弹性空间,从而实现从方案设计到价值交付的全链条闭环。具体而言,推理方案设计应遵循以下关键原则:
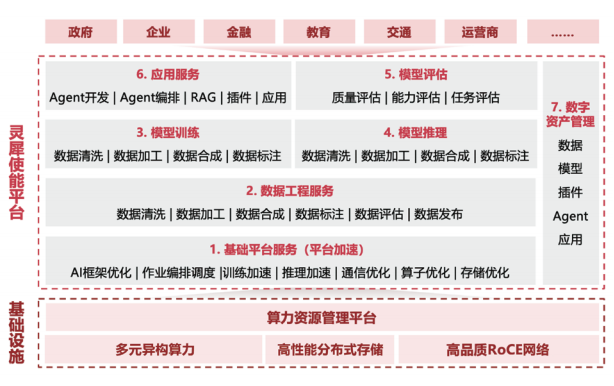
AI业务平台可为用户提供一站式大模型全生命周期服务平台,提供大模型工程化能力和AI应用使能服务能力。
基础平台服务通过算、运、存全方位协同加速,构建高效能技术底座。计算层面,训练阶段采用自适应切分策略提升资源利用率,推理过程借助KVCache、PD分离及模型量化技术优化响应速度;通信模块依托UCCL(新华三自研统一集合通信库)收集网络拓扑信息,实现智能调度,大幅提升集合通信性能;存储系统则集成数据缓存、FlashCheckpoint、镜像预热及P2P加载等功能,减少数据读写延迟。数据工程服务贯穿大模型全生命周期,从原始数据采集、清洗、标注到调优,提供全流程数据治理,确保模型训练与推理的高质量数据供给。
模型训练与推理环节展现平台核心技术优势。通过AI集群一键部署与压测功能,降低项目启动成本;训练任务秒级监控与分钟级恢复机制,多维度提升有效训练时间占比。自研推理引擎结合模型量化等优化技术,实现推理性能30%以上的跃升,同时支持多元模型、异构推理、自动扩缩容及多业务负载,有效降低推理成本。模型评估模块构建双轮评测体系,既评估模型基础能力,又验证应用效果,涵盖通用、领域、行业及自定义评测场景,预置27个子类评测集与超10万道评测题,通过自动化流程保障模型迭代的精准性。
在应用与管理层面,平台以低门槛、可视化交互方式,构建高效应用开发环境。丰富的插件集与灵活编排能力,使开发者可在分钟级内完成智能应用搭建。数字资产管理系统将数据集、模型、镜像等核心要素纳入统一管理框架,通过属性分类与元数据分离策略,提升资源检索与调用效率,为大
推理场景中,根据模型规模、计算需求及系统性能目标的差异,GPU呈现出四种典型运行形态,为多样化的推理任务提供精准适配的计算方案。
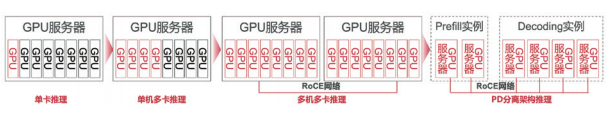
单卡推理是最基础的运行模式,适用于模型参数规模较小、单卡显存足以容纳模型数据并支撑运行的场景。以Qwen-32B模型为例,其参数量级在单张GPU的显存承载范围内,通过单卡部署即可高效完成推理任务,简化了硬件资源配置与任务调度流程。
当模型参数量超出单卡显存容量,但仍在单台服务器GPU总容量限制内时,单机多卡推理模式成为优选方案。这种模式通过并行计算与显存共享机制,将模型参数与计算任务拆分至多张GPU协同处理。如Llama-70B模型,在单卡无法独立承载的情况下,可通过4张GPU并行运算,实现推理性能与资源利用率的平衡。
对于参数量巨大的超大规模模型,或对高并发、高可用性有严格要求的场景,多机多卡推理发挥关键作用。一方面,当单台服务器8张GPU的显存仍无法满足模型与长上下文运行需求时,借助RoCE(RDMA over Converged Ethernet)网络,多台服务器间的GPU可实现高效无损的数据传输,确保跨服务器的计算结果实时交互,典型案例如DS-671B模型通过16张GPU跨机协同完成推理。另一方面,为满足用户高并发访问需求并保障系统稳定性,多机多卡推理可部署多个推理实例,通过负载均衡器动态调度用户请求,同时采用服务器级非亲和性调度策略,避免单点故障,例如DS-671B模型部署两个独立实例,分别运行于不同节点,通过负载均衡显著提升系统并发处理能力与可靠性。
另外,在规划GPU显存时,除了装载模型的参数,常常会预留一部分显存作为KVCache。假设模型的计算公式为A*B*C*D,用户的输入为X,用户的输出为Y,那么模型的推理计算公式为Y=X*A*B*C*D,在计算机计算过程中,是按照顺序一步一步计算的,那么X*A的值a就需要显存暂存,用于计算下一步a*B,后面的一此类推,类似a的中间值即为KVCatch。
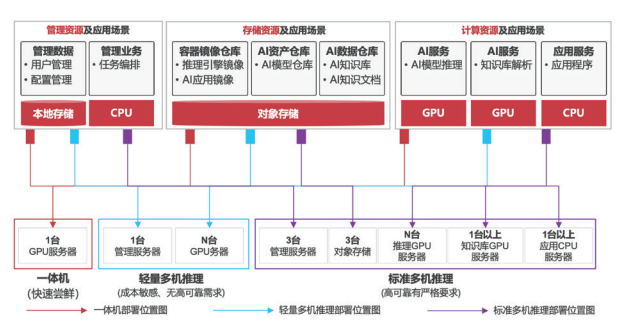
在AI应用落地的过程中,业务部署架构需根据场景需求、成本预算与可靠性要求,提供差异化的技术方案。当前主流部署模式可划分为一体机、轻量版多机推理、标准版多机推理及训推一体架构,形成覆盖从快速验证到复杂研发的全链条解决方案。
一体机采用单台服务器承载管理、模型推理、应用服务及数据存储的全功能架构,通过高度集成化设计实现业务的快速部署。其核心优势在于“开箱即用”——无需复杂集群配置,即可满足单个推理实例的测试场景或小批量业务需求。例如,单台服务器同时运行管理模块、推理引擎与应用服务,同时存储管理数据与业务数据,特别适合对高并发、高可靠性无严格要求的中小企业快速验证AI场景价值,如内部知识问答系统或简单数据处理工具的落地。
针对2~4台GPU服务器的小规模部署需求,轻量版多机推理架构通过资源复用实现成本优化。该模式中,管理服务器除承担集群调度与存储服务外,若GPU服务器运行如DS-671B等大模型时无额外显存承载知识库,管理节点还需兼任知识库与应用服务的运行任务;推理GPU服务器则独立规划,专注模型计算。这种架构舍弃部分冗余设计,适用于预算有限且无需高可靠保障的场景,如创业团队的大模型初步应用、教育科研领域的小规模推理实验,可支持1~2类模型的并行推理。
对于8~16台GPU服务器的中型集群,标准版多机推理通过模块化设计构建高可靠体系。其核心部署逻辑包括:独立的管理服务器专职集群调度,避免业务干扰;对象存储系统实现数据集中管理与备份;知识库服务器采用2台热备架构(HA),确保应用服务的连续性;推理GPU服务器则根据模型规模按需配置。该架构典型应用于企业级AI服务,如客服机器人、智能文档处理等场景,可同时支持4类模型的推理任务,通过负载均衡与故障切换机制,满足7×24小时业务连续性要求。
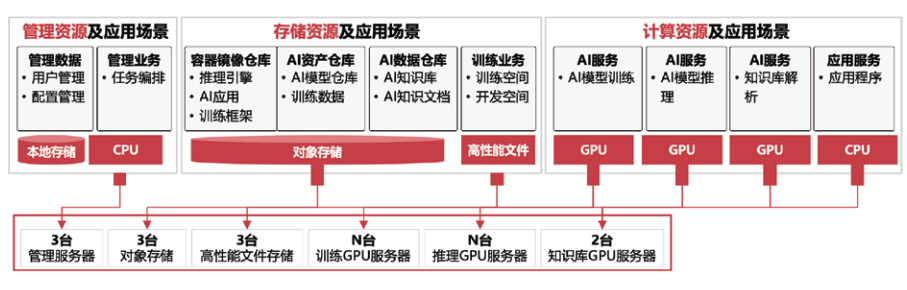
面向模型研发场景中训练与推理的协同需求,训推一体架构通过资源分区策略实现“训推无缝衔接”。其核心分为两种模式:
软分区模式采用RoCE网络将所有GPU组成统一算力集群,训练与推理资源可动态调配。例如企业内部大模型研发时,优先保障训练任务的算力需求,推理环节仅用于模型效果测试与应用对接,这种灵活调度适用于以训练为核心、推理为辅助的场景,如AI算法团队的模型迭代优化。
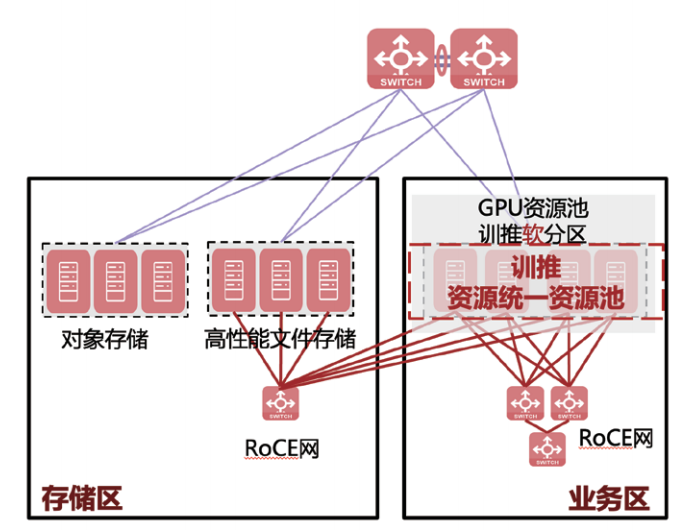
硬分区模式则划分独立的训练资源池与推理资源池:训练节点连接高性能文件存储以支撑大规模数据读取,推理GPU服务器可按需接入RoCE网络。该模式适用于以推理为核心的场景,如企业基于开源模型构建私域应用时,仅需少量训练资源用于模型微调,大量资源专注于推理服务的高并发响应。
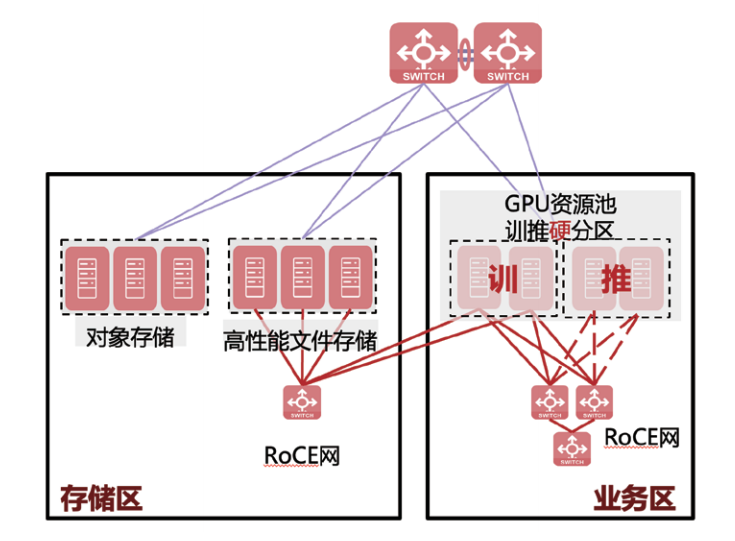
从单机集成到训推一体,不同部署架构通过硬件资源与软件逻辑的差异化设计,精准匹配企业从概念验证到规模化应用的全周期需求。未来,随着AI模型规模与业务复杂度的提升,部署架构将进一步向“弹性调度、智能感知”方向进化,实现算力资源的极致利用与业务连续性的全面保障。

在人工智能研发进入工程化深水区的背景下,新华三灵犀使能平台正通过系统性技术架构重构,为企业算法团队打造从开发到落地的全链路加速引擎。该平台以GPU虚拟化技术为基础为该医疗器械公司构建百人级协同开发环境,依托弹性算力集群实现分布式训练与推理的资源智能调配。
在资源管理层面,平台实现训练与推理资源的统一池化管理,支持根据业务优先级动态分配GPU、存储等硬件资源,确保训推业务高效流转。例如,训练任务管理模块可自动协调多节点算力,实现大规模训练任务的并行调度;多存储数据备份机制则通过分布式文件系统冗余策略,保障训练数据的可靠性与可追溯性。并针对性解决企业研发场景中常见的跨团队训练数据资源共享、海量数据上传等痛点。
平台在模型训练优化领域展现出显著技术优势。以开源Llama-70B模型训练为例,基于4台H20 GPU的硬件配置,通过网络架构与模型工程的双重调优,实现了里程碑式的性能突破:在处理10M Token数据时,训练时间从客户预期的50分钟大幅缩短至24分钟,关键指标MFU(机器浮点运算利用率)从40%提升至84%。
灵犀使能平台以训推一体化为核心的技术架构,正在重新定义AI算力服务的标准。从资源调度的智能化到训练效率的极致优化,其技术实践不仅解决了企业AI研发中的算力瓶颈问题,更通过工程化能力的沉淀,推动AI应用从实验室走向大规模产业落地的进程。未来,随着大模型技术的持续演进,该平台将进一步深化算力与算法的协同优化,为企业在AI时代的技术创新提供更强劲的动力引擎。
